


托纳姆物语编程系列(4)——如何检查背包?
修改于2024/05/29644 浏览整活专区
每天写这个的时间有限,加上这次这个确实有一点难度,这次我们先看效果在逐次讲解
没识别出来一部分一是因为我们用的OCR官方给的默认模型对特殊符号支持并不是很好,二是截图速度的问题,这个截图确实很影响整个代码的运行效率但我目前也没找到能简单抓到手机屏幕视频流的方法。
开始
以我们自己的角度来看,我们去点选背包格的时候我们会下意识的去看格子的边框去找到格子的中心,然后去点击中心就完成 了格子的点选,但是我们先整体看一下背包
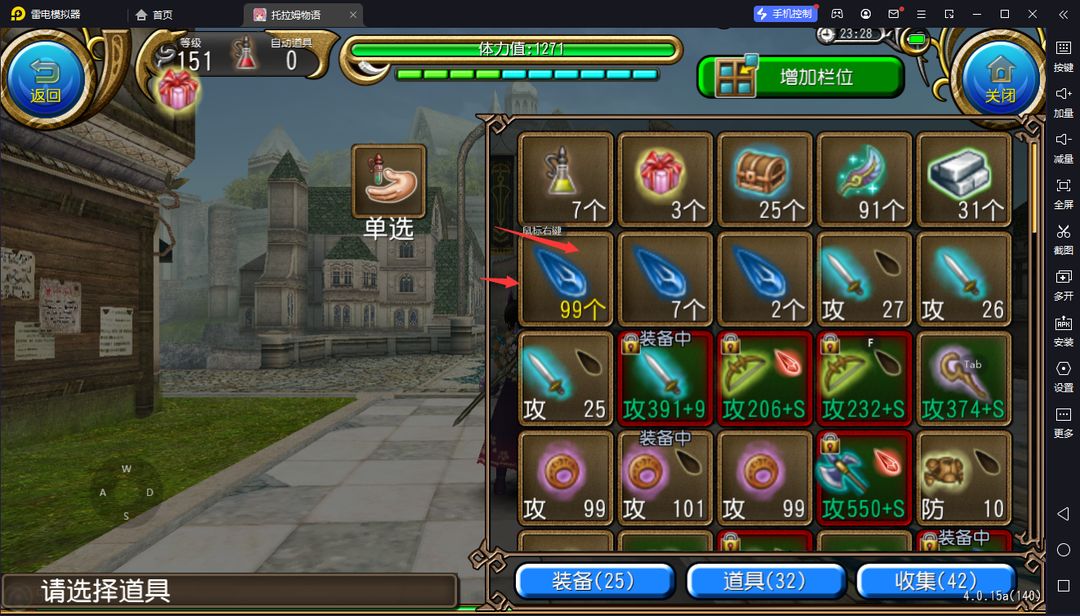
虽然边框的颜色和格子内的颜色有一定区别但是,色调是一样所以,我们不得不缩小阀值,但这不可避免的会降低我们程序的鲁棒性,我们二值化出来看一下

二值化
可以看到整体出来不但有相当多的噪声,边框也有很多断点,所以如果仅仅这样是不够的,我们接着往下处理。首先我们先过滤噪点,调用高斯模糊做一个过滤,具体可以自己搜索了解一下,再做个边沿处理
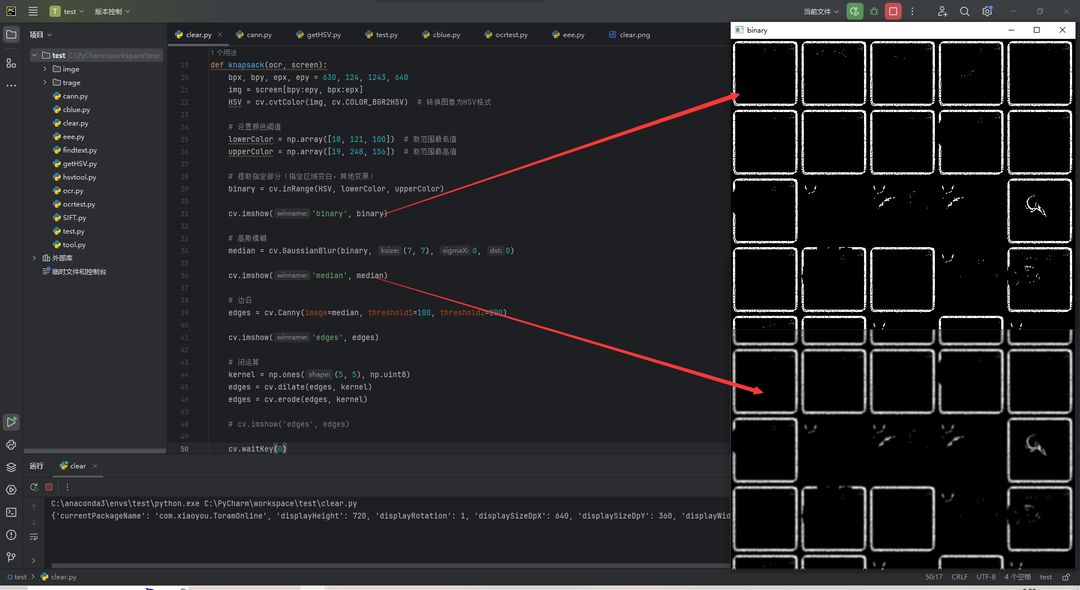
分别是二值化和高斯模糊后的结果
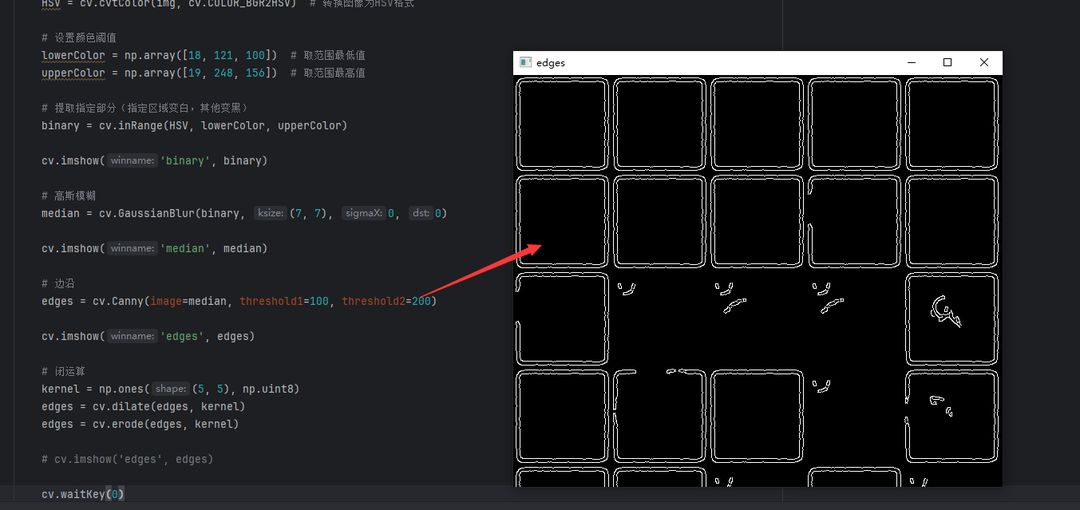
边沿检测
可以看到最终出来的边沿检测图像还是很清晰的,我们现在只需要在做一个下形态学的闭运算把整个框架变得更加明显
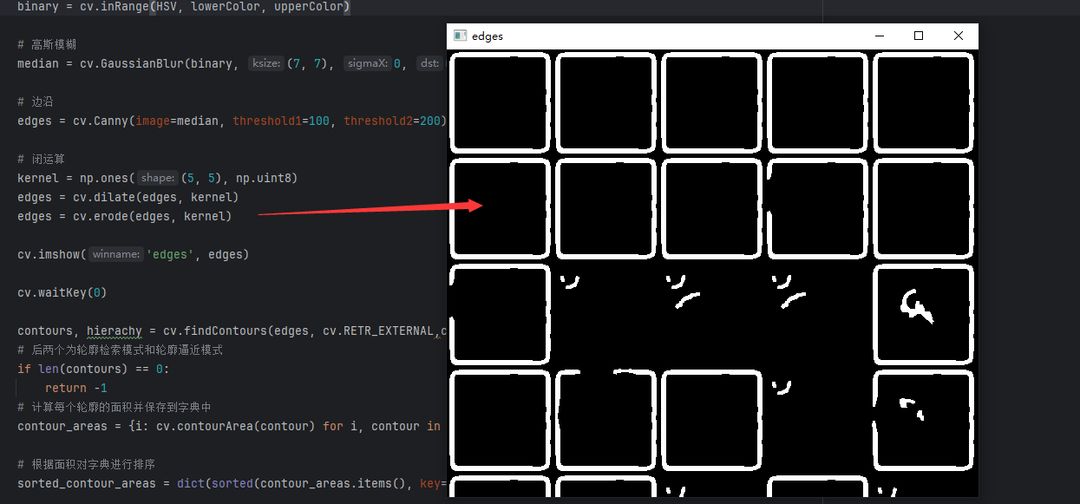
闭运算之后的图像
在做闭运算之后可以我们就可以很清晰的看到整体轮廓了,现在我们只需要调用opencv的轮廓检索
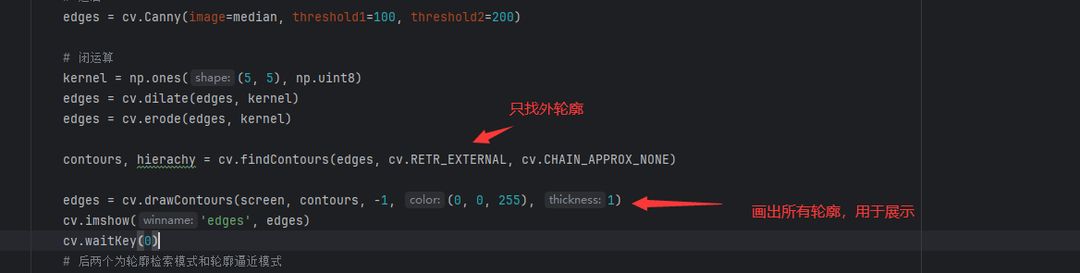
先看一下代码

效果图
可以看到轮廓已经很清楚的找出来了,但是有一个问题,还是有好呢多的误判,因此我直接用系列2的方法用求轮廓面积的方式过滤掉残缺的轮廓,但是不可避免的如下图所示这些因为这些有孔的装备,导致装备上的光圈溢出来让轮廓不完整,所以这些也会被我们当成错误的数据


到这里,大部分就结束了,我们看一下主函数调用

结束


import cv2 as cv
import uiautomator2 as u2
import time
from paddleocr import PaddleOCR
import numpy as np
def gettext(ocr, img):
ocr_text = ocr.ocr(img, cls=False) # 进行识别
ocr_text = ocr_text[0]
if len(ocr_text):
out_text = ocr_text[-1][-1][0]
return out_text
else:
return ""
def knapsack(ocr, screen):
bpx, bpy, epx, epy = 630, 124, 1243, 640
img = screen[bpy:epy, bpx:epx]
HSV = cv.cvtColor(img, cv.COLOR_BGR2HSV) # 转换图像为HSV格式
# 设置颜色阈值
lowerColor = np.array([18, 121, 100]) # 取范围最低值
upperColor = np.array([19, 248, 156]) # 取范围最高值
# 提取指定部分(指定区域变白,其他变黑)
binary = cv.inRange(HSV, lowerColor, upperColor)
# 高斯模糊
median = cv.GaussianBlur(binary, (7, 7), 0, 0)
# 边沿
edges = cv.Canny(image=median, threshold1=100, threshold2=200)
# 闭运算
kernel = np.ones((5, 5), np.uint8)
edges = cv.dilate(edges, kernel)
edges = cv.erode(edges, kernel)
contours, hierachy = cv.findContours(edges, cv.RETR_EXTERNAL, cv.CHAIN_APPROX_NONE)
# 后两个为轮廓检索模式和轮廓逼近模式
if len(contours) == 0:
return -1
# 计算每个轮廓的面积并保存到字典中
contour_areas = {i: cv.contourArea(contour) for i, contour in enumerate(contours)}
# 根据面积对字典进行排序
sorted_contour_areas = dict(sorted(contour_areas.items(), key=lambda item: item[1], reverse=True))
# 获取排序后的轮廓索引
sorted_contour_indices = list(sorted_contour_areas.keys())
for i in sorted_contour_indices:
if contour_areas[i] < 13000:
break
M = cv.moments(contours[i])
if M["m00"] != 0:
cX = int(M["m10"] / M["m00"])
cY = int(M["m01"] / M["m00"])
d.click(cX+bpx, cY+bpy)
text = d.screenshot(format='opencv')
延时0.05秒
print(gettext(ocr, text[429:463, 47:441]))
if __name__ == "__main__":
d = u2.connect()
print(d.info)
延时一秒
screen = d.screenshot(format='opencv')
# 例如`ch`, `en`, `fr`, `german`, `korean`, `japan`
Ocr = PaddleOCR(use_angle_cls=False, use_gpu=False,
lang="ch", show_log=False) # need to run only once to download and load model into memory
while True:
#print(screen[624, 1266])
screen = d.screenshot(format='opencv')
if np.equal(screen[624, 1266], np.array([149, 154, 154])).all():
break
knapsack(Ocr, screen)
d.swipe(1118, 500, 1118, 117, 0.05)
延时0.5s