

托纳姆物语编程系列(3)——如何区分鸟类翅膀和厚鸟喙
修改于2024/05/26854 浏览整活专区
兽品图标都是一样的,区分的唯一标准就是汉字,所以我们得让脚步学会识字,幸运的是OCR已经是十分成熟的计算了我们只需要几行简单的命令就可以实现文字识别。
一丶环境安装
这里直接贴上连接,gitee上的开源项目汉字说明都很详细就不多说了。
二丶代码编写
众所周知,物品名称出现的都是固定位置,所以我们只需要固定识别这个范围内的图文就可以了
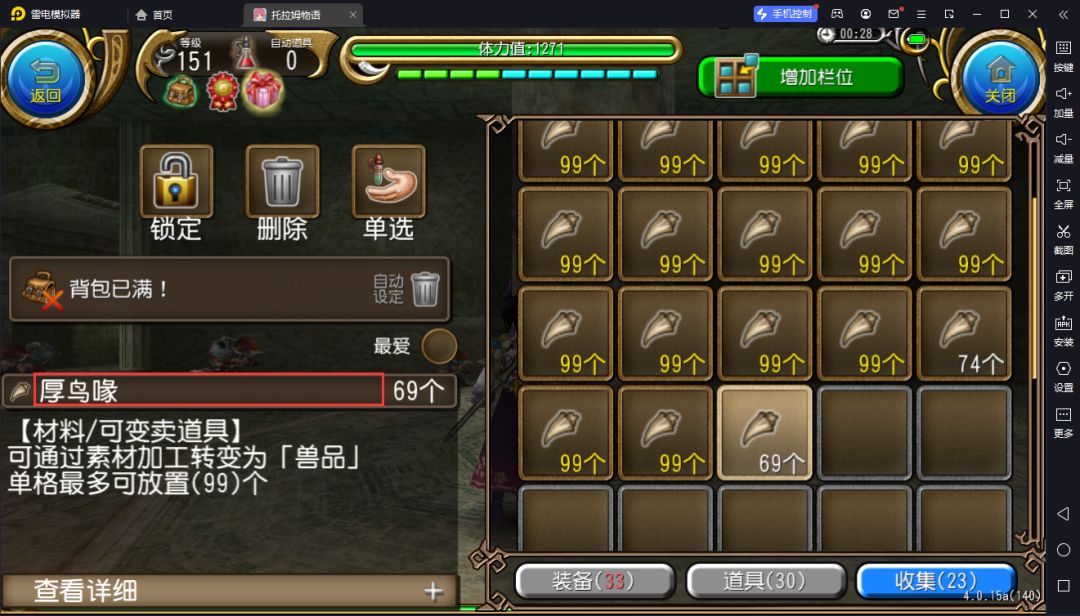
现在终端输入uiauto.dev借助uiautodev获得图文信息
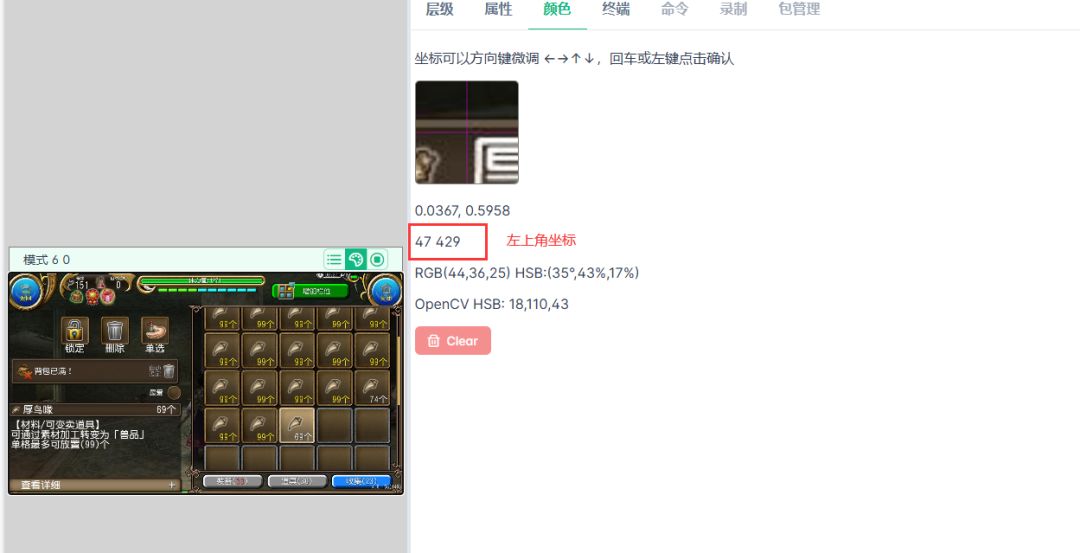
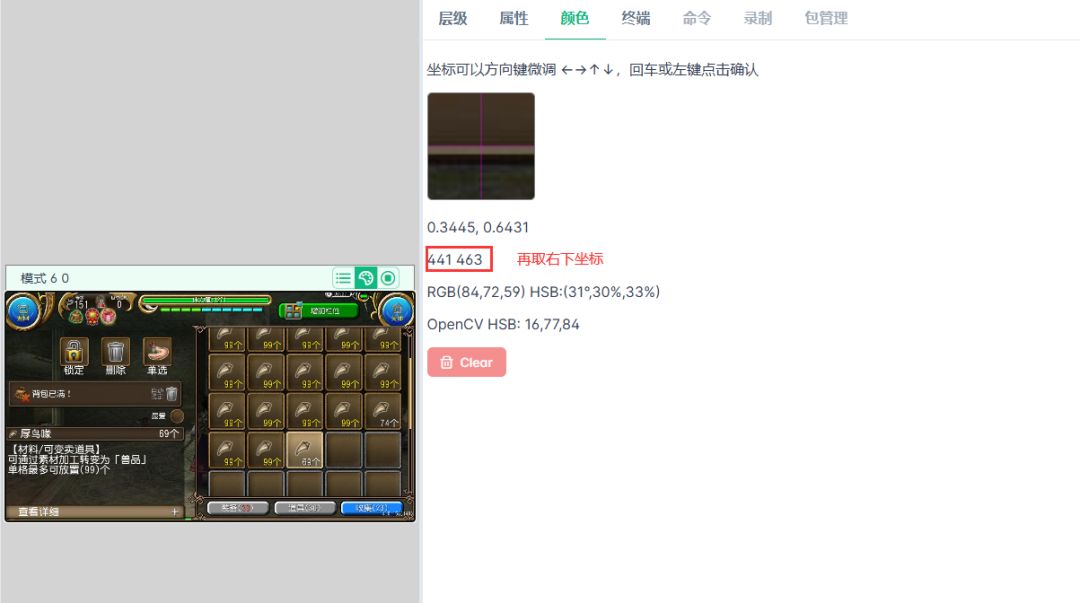
一行代码就可以裁剪出来了,一定要注意参数填写的顺序
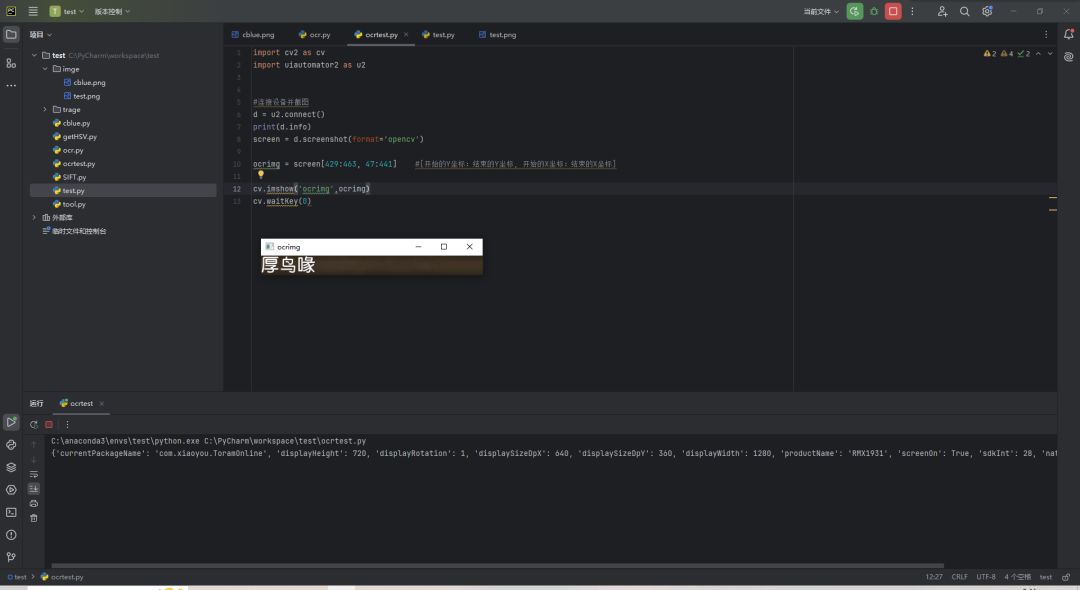
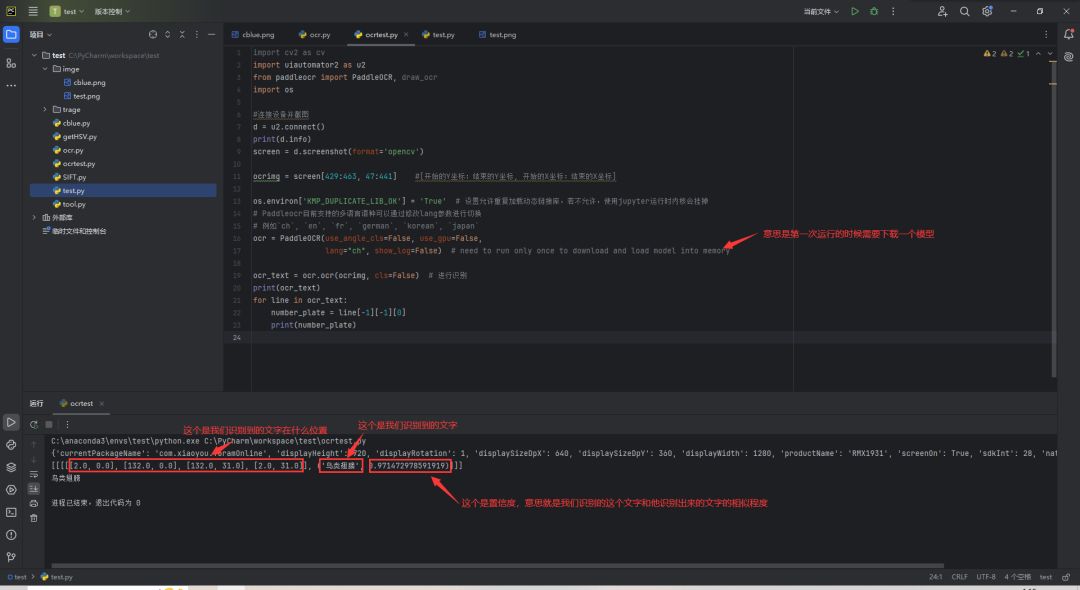
上面PaddleOCR函数里具体参数详解可以看下面这个链接
代码就放这里


import cv2 as cv
import uiautomator2 as u2
from paddleocr import PaddleOCR, draw_ocr
import os
#连接设备并截图
d = u2.connect()
print(d.info)
screen = d.screenshot(format='opencv')
ocrimg = screen[429:463, 47:441] #[开始的Y坐标:结束的Y坐标, 开始的X坐标:结束的X坐标]
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True' # 设置允许重复加载动态链接库,若不允许,使用jupyter运行时内核会挂掉
# Paddleocr目前支持的多语言语种可以通过修改lang参数进行切换
# 例如`ch`, `en`, `fr`, `german`, `korean`, `japan`
ocr = PaddleOCR(use_angle_cls=False, use_gpu=False,
lang="ch", show_log=False) # need to run only once to download and load model into memory
ocr_text = ocr.ocr(ocrimg, cls=False) # 进行识别
print(ocr_text)
for line in ocr_text:
out_text = line[-1][-1][0]
print(out_text)
我们可以看到paddleocr的强大功能不仅仅局限在这里面,它还可以用作文本定位所以我们可以用来完成一个相对复杂的功能,比如找到我好友列表的指定一个人给他发送一个邮箱。
这里就给我第一次玩托纳姆物语遇到的第一个朋友发一条消息
代码放在后面
不知道为什么不能出现time。sleep(1),哎这taptap
下面的延时一秒应该是
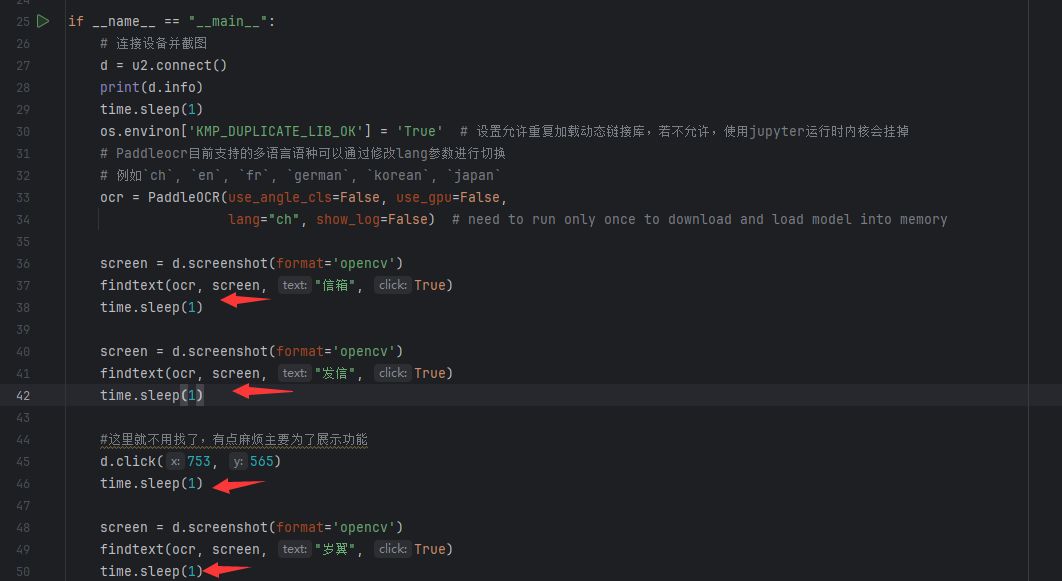
import time
import cv2 as cv
import uiautomator2 as u2
from paddleocr import PaddleOCR, draw_ocr
import os
def findtext(Ocr, img, text, click=False):
center_x, center_y = -1, -1
result = Ocr.ocr(img, cls=False) # 进行识别
result = result[0]
print(result)
for line in result:
if line[1][0] == text:
bbox = line[0]
xy1, xy2, xy3, xy4 = bbox
center_x = (xy1[0] + xy3[0]) // 2 # 计算中心点横坐标
center_y = (xy1[1] + xy3[1]) // 2 # 计算中心点纵坐标
if click:
d.click(center_x, center_y)
return center_x, center_y
if __name__ == "__main__":
# 连接设备并截图
d = u2.connect()
print(d.info)
延时一秒
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True' # 设置允许重复加载动态链接库,若不允许,使用jupyter运行时内核会挂掉
# Paddleocr目前支持的多语言语种可以通过修改lang参数进行切换
# 例如`ch`, `en`, `fr`, `german`, `korean`, `japan`
ocr = PaddleOCR(use_angle_cls=False, use_gpu=False,
lang="ch", show_log=False) # need to run only once to download and load model into memory
screen = d.screenshot(format='opencv')
findtext(ocr, screen, "信箱", True)
延时一秒
screen = d.screenshot(format='opencv')
findtext(ocr, screen, "发信", True)
延时一秒
#这里就不用找了,有点麻烦主要为了展示功能
d.click(753, 565)
延时一秒
screen = d.screenshot(format='opencv')
findtext(ocr, screen, "岁翼", True)
延时一秒
d.click(731, 233)
d.send_keys("好久不见")
d.press("enter")
d.click(593, 393)
d.send_keys("对不起,是我先不辞而别了,还能在回来看看吗?")
d.press("enter")