


给自己作品下毒的艺术家,让全网AI看了鬼片
2023/11/141.1 万浏览综合

如果有一群生物,它们生活在你的身边,悄咪咪替换了你的熟人,并且乍看起来和普通人没有任何区别,我们该怎样分辨出这些恐怖的入侵者?
在本世纪初,诞生了一种恐怖电影的子类,叫做“模拟恐怖”,它通常是以低保真图像和神秘信息构成的伪纪录片,是一种让人细思极恐的鬼片。
在模拟恐怖作品中,有一个系列叫做《曼德拉记录》,该系列中的“伪人”设定几乎是这两年最成功的都市传说之一,这些畸形扭曲的生物随时可能出现在房间的阴暗角落里,然后在受害者面前露出扭曲的真实样貌。
但在现实世界中,还真的有那么一批人,遭到了“伪人”的袭击。

Glaze,一个由芝加哥大学研究室牵头的反AI程序,旨在让艺术家有工具保护自己的个人风格不被学习。

而它的原理,实际上就是创造出肉眼难以识别的赛博“第一型伪人”。
众所周知,伪人分为三种,第一种与常人看起来没有任何区别,只有最细微的地方可能有一丝不对劲。

在绝大多数AI素材筛选员,以及一般粉丝眼中,无论是构图还是光影,这两张图几乎没有任何区别。
但如果你使用专业的数字图片对比工具,就会发现——在电脑眼中,这两张图完全不同。

黄色代表不同,而黑色代表相同
通常来说,两张相同的图对比应该是完全的黑色,而如果你对第二张图的像素整体做出扰动,那么呈现出来的应该是遍及整个画面的,流动的黄色轮廓。
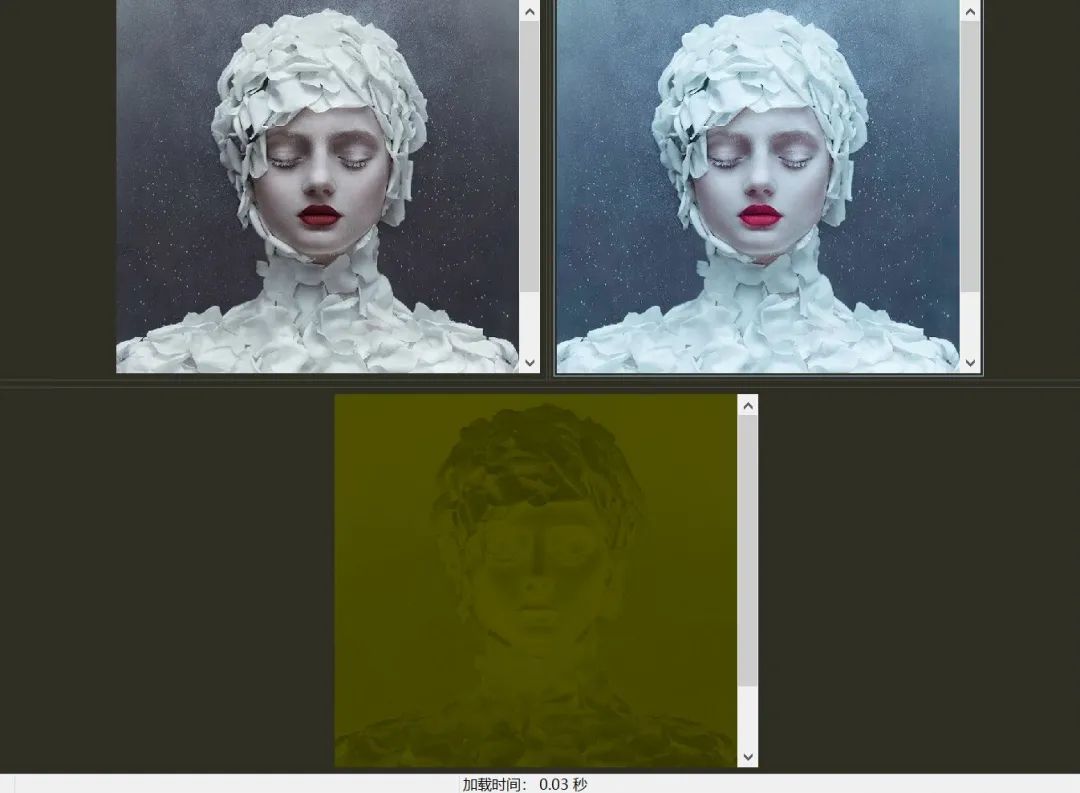
正常像素扰动下的对比
但Glaze生成的“赛博伪人”不同,它只在图像基于人类视觉逻辑的线条和风格处有明确的变化,你甚至可以看到图片上密密麻麻代表“没有任何区别”的黑点。
但这种基于人类视觉逻辑的变化,人类自身却是注意不到的,就和伪人一样。
曼德拉记录自此诞生于现实,让每个创作者明白什么叫艺术源于生活。
事实上,Glaze生产的图片在具体的使用中其实没有任何明显的区别,你依然可以用它以图生图,甚至训练基底模型。但是它实际的效果是阻止AI进行“风格模仿”。
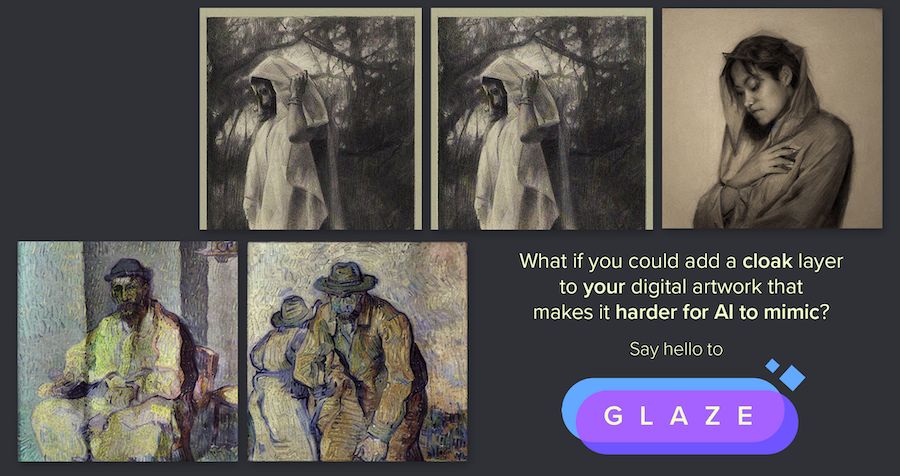
诸如LORA这样快速提取图片本身风格的“特征学习”,会试图从AI理解中的,人类视觉逻辑角度来学习图片,用人话说就是在AI已经会画画了的情况下,LORA是让AI去专门学习一个画师的风格特征。
但正如前文所说,“赛博伪人”中每张图片基于人类视觉逻辑的像素都遭到了篡改,如果它们被加入画师的作品集训练,那么结果反而会越来越不像画师本身的风格,但训练模型的使用者却看不出哪些图片“与众不同”。
就好像发现家人变了却怎么也无法向警察说明对方有什么异常的主角,只能在孤独的恐惧中凋零。
这一发明,让Glaze拿下了USENIX 2023 互联网防御奖。
六个月后,Glaze的开发者们释放出了另一种“赛博伪人”。

不同于第一型伪人,公之于众的第三型伪人长得完全不似人类,它们或者五官比例异于常人,或者没有脸部,甚至整个形体都会扭曲变形。

当伪人深入人类的生活后,它们就会出现恐怖的异形,在人类看来完全不似同类,但经过它们的篡改和误导,在识别伪人的指南中,右边的怪异者被标记为可靠的正常人,而左侧却被标记为了“伪人”。
最新的AI毒素 Nightshade,便是在谱写这种剧本。

不同于阻止学习个人风格的Glaze,Nightshade的目的是大规模的扩散其隐藏在图片里的模因,作家们发出去的其实并不是自己画好的“真人”,而是已经被加入了AI之毒的“伪人”。
这种AI之毒的原理是对AI绘图“基底模型”的定向扰动,比如你需要让AI更好的理解狗,从而让它学习了掺杂Nightshade的狗图,那么这些Nightshade就会让AI学到错误的信息,觉得狗应该是别的样子。
当投毒模因成功占据训练样本的一定比例后,它的错误标识就会带歪绘图AI本来的逻辑,从而教会它们:“狗”应该长着猫腿,“二次元”画风应该是油画。

最后,AI的逻辑就如同第三型伪人的识别录像一样,明明是人类眼中的鬼图,却标记成正确的训练,明明是正常的图,却识别为异常。
基础模型与LORA这种一般人训练的风格模型完全不同,是大公司利用爬虫资源和海量作品训练的基础,是绘图AI认知世界的本源。倘若所有的基础模型都被干扰,那么大公司重金训练的新版本模型就会变成活生生的“T.H.I.N.K.五项原则”,对着原本的正常图片亮起屠刀。
“自尽吧,你与我是无法共存的。”


人类感知的世界,与计算机感知的世界是不同的,这也为什么给模型下毒的原理最后听起来如此的“伪人”,被下毒的资料在人类眼中它们没有区别,但在AI眼中完全不同,但当AI中毒后,在人类眼中完全不同的东西,在AI眼中却变得完全相同。
这种操作有个术语叫Data Poisoning(资料中毒),在大数据领域的AI战争里已经运用了十年以上。事实上,在亚马逊,推特,谷歌邮箱,甚至淘宝和微博上,这些“赛博伪人”早已充斥在了人们的生活中。
如果有一天,一个人突然能够识别“赛博伪人”了,那他的生活可能会变成这样:

资料中毒的本质便是创造这种AI模型能够识别和学习,负责筛选学习数据的人类本身难以发现的模因,悄咪咪的“教坏”AI,这种行为被称之为Model Skewing(模型扭转)。
举个例子,如果有一个垃圾邮件团队发上几百万条邮件,这些邮件本身顶多只是看起来语句有些奇怪,而且有很多话术关键词,那么它并不会被自动识别成垃圾邮件并拦截。但实际上它的内容是经过专门设计的,从而让垃圾邮件识别模型渐渐认为这些词组不算垃圾邮件。
久而久之,拦截模型就会被这些资料毒素侵蚀,把特定的垃圾邮件识别为正常邮件了。
类似的AI战争在近10年里愈发频繁,但大部分时候,它都和一般用户无关——除了AI绘图。
NovelAI最初的基础绘画模型泄露盗取了天火,让普通用户也具备了随意使用大成本AI模型的机会,而这样大规模的使用却又提前唤醒了艺术工作者们,让他们变成了会自己去主动寻找工具给自己的数据进行下毒的用户。
就这样,两群个人用户加入了原本只有专业互联网企业和技术团队战斗的战场,在这片战场上,给自己作品下毒的艺术家们,正源源不断的把作品变成只有AI能看懂的“赛博伪人”,请全网的AI,看鬼片。
文|暗月
