



我被货不对板的AI宣传图打倒了
2023/07/143 万浏览综合

GPT-4模型已经发布。相比年初的热火朝天,模型的更新仿佛正在变的稀松平常。不管是人工智能还是人工智能生成内容,都在产生更加实际的影响。
自从AI绘图进入实际应用层面,有一件小事正在对我造成困扰:货不对板的游戏越来越多了。
我的工作内容,包括收集各种渠道的热门游戏和话题。红烧牛肉面里面没有肉,老婆饼没有老婆,从宣传图到实机动画的距离到底有多远,做的久了自然知道。但最近,广告的质量越来越高,游戏的品质却跟之前没什么区别。甚至,还会因为货不对板的落差,更加割裂。
我是一个杂食的女性向玩家,什么女性向游戏都会玩一下。吃多了清汤挂面,也会想吃点刺激的东西。所以当信息流推荐里面,出现这种面目姣好可攻可受的少年人的时候,确实有好奇点进去看看的冲动。

但是,点进去看到的是——亮闪闪首冲奖励,福利大转盘,还有十年之前的人模和服装设计……对不起,打搅了,我对你有一些不切实际的期待。我们好聚好散,我不算计你的色相,你也不要算计我的钱包。
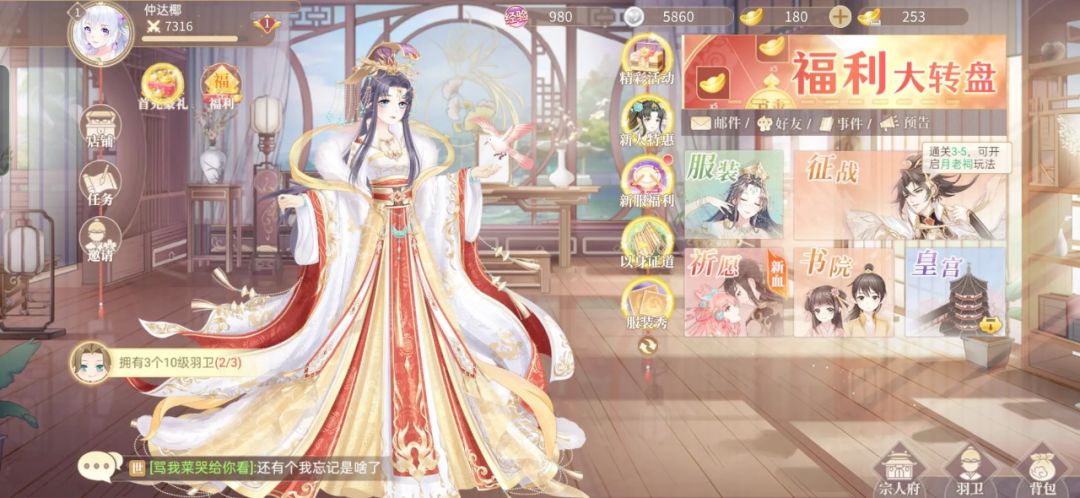
这也不是女性向宫斗游戏独有的现象。AI生成图像的确帮助很多项目提升了生产效率,也让我见到一些不存在的好游戏。现在,游戏是存在了,但图片跟实机的距离有点遥远。
我想玩机甲游戏,《泰坦陨落》或者《圣歌》的机甲设计各有千秋,看着也十分酷炫。大数据收到了我的期待,于是给推荐了这个游戏。

但点进去,原来是横版的“剑与远征”,而且画风还是宝宝巴士风格。人不能两次踏入同一条河流,但是可以多次被类似的理由欺骗,骗了又骗。
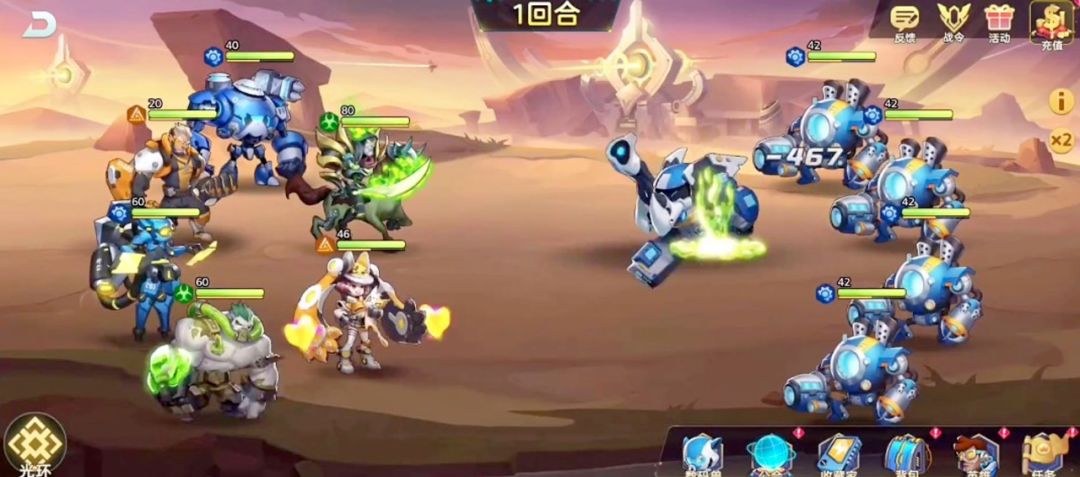
诸如此类的“宣传仙人跳”,看一次两次还好,看久了就让人心里疲惫。在宣传图阶段,看的是美美的网红照片,下载之后拿掉滤镜,发现竟然是宝宝巴士,浪费期待流量内存和时间。
这种信息的误导,不仅发生在游戏领域,甚至已经入侵生活,造成明确的经济损失。包头公安日前破获了一起“AI诈骗”案件,犯人通过换脸、音频模拟,通过微信拨打电话的方式,骗取被害人信任。10分钟电话,诈骗金额接近430万元。
以上的例子都是立竿见影,在当下造成了明确损失,或者信息的偏差的。更麻烦的是,AI生成内容对于人类知识库的潜在污染。如果你现在以“小孔雀”为关键词在搜索引擎中搜索,会发现“小号的成年孔雀”和“刚刚出生的棕毛孔雀”出现在同一屏。如果你并不知道“鸟类生下来的时候都很丑”,会不会把AI生成的图片,当成客观的自然现象呢?
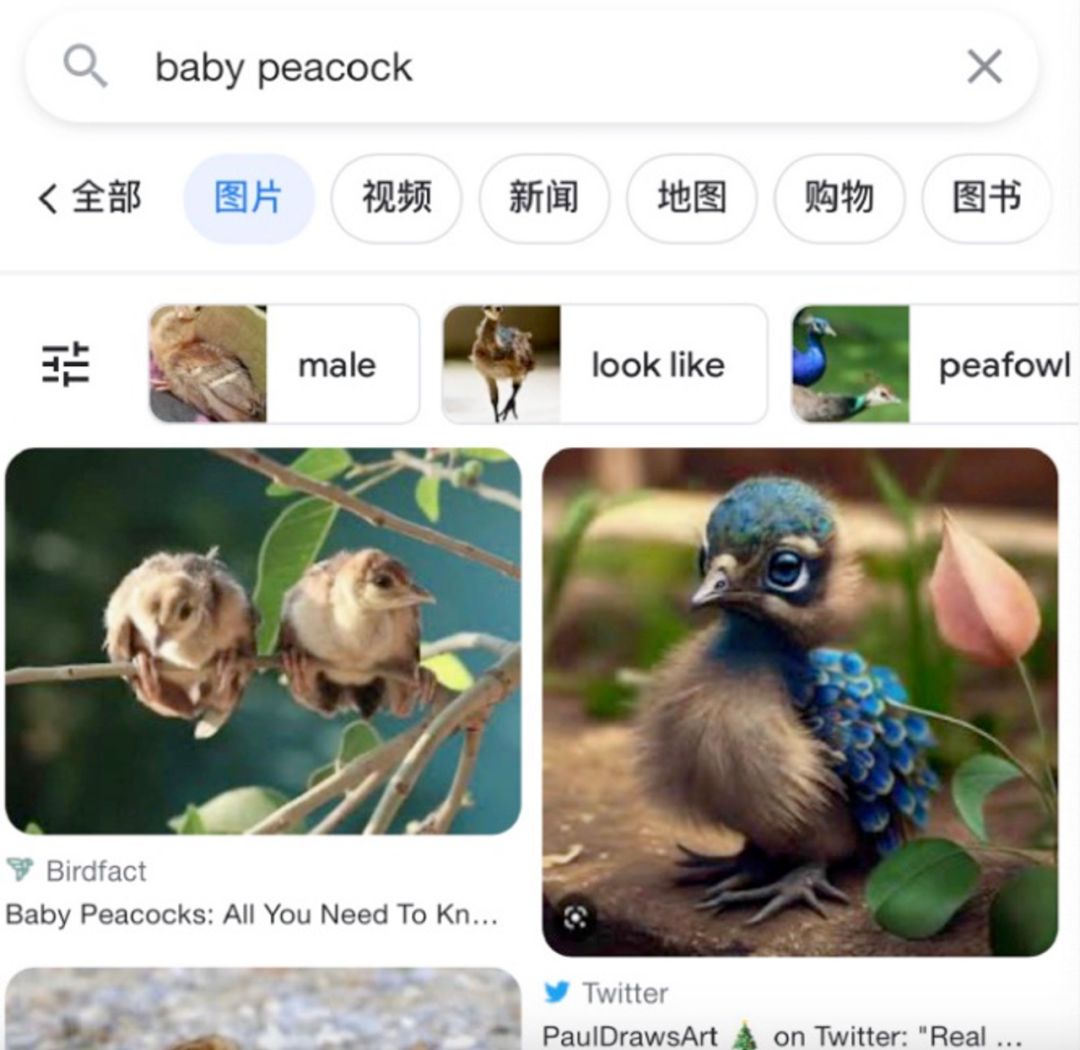
左:真正的小孔雀,右:AI图
当然了,有人或许要举例子:《刀剑乱舞》和《舰队收藏》这种,搜索一个船的名字能出来十七八个老婆,也是在污染搜索结果。但“舰娘拟人”和“船只本身”差距拉开得够大,怎样都不会以为现代航母战争,都是靠一群体重一吨的美少女打下来的吧?但是“小孔雀”是一个有足够迷惑性的信息,从逻辑上,小号成年孔雀更符合逻辑上的推理。但现实就是,小孔雀生下来的时候很丑,跟小麻雀一样丑。
AI的出现带来了新形式的内容产出,比如说可口可乐就利用了AI生成内容会产生的模糊和抖动,拍出了一支混搭各种艺术流派的影片。但同样,它也给我们造成了令人迷惑的困扰和判断,在评价一个东西好不好,真不真之前,“是不是算法生成的内容”,这个问题被置于所有评价之前。它不光是位于猜疑链的顶端,同时,像是一柄达摩克利斯之剑一样,平等地审判所有能看到的内容。

世界辽阔,这种“小事件改变全世界”的事情,之前也有发生过的例子。比如说,用于高端测量仪器制造的“低本底钢”。
低本底钢,别名“先原子钢”“低背景钢”,指的是产出于1940-50年代之前的钢材。由于冷战前后的核试验,以及长崎广岛两地的原子弹爆炸,导致全世界的背景辐射水平升高。钢材炼制需要大气参与反应,所以,1950之后,全球产出的钢材,都被环境中的放射性同位素污染,本身就有更高的辐射水平。而1940年之前产出的钢材,则没有这种“背景辐射”。你可以通过打捞1940年之前的沉船,获得这种更干净的钢材。这种“低本底钢”,通常用于制造精细测量设备,比如说航空航天的传感器,盖革计数器,部分医学测量仪器。
总结一下,原子弹爆炸的影响,不光发生在人类看得到的那些地方。在接下来的一个世纪,改变了整个大气圈的背景辐射,进而影响了人类自己的生产和生活环境。

AIGC的出现,对于内容生产领域来说,无异于“原子弹爆炸”,炸出了大量的内容,也产生了巨大的隐患。2023年之前的网络数据,会成为数字时代的“低本底钢”。因为在2023年之前,互联网不存在大量的机器生成内容,无污染,无添加,纯手工输入。
这种信息污染,甚至有可能威胁到人工智能本身的开发进度。牛津大学、剑桥大学、多伦多大学最近联合发布了一篇关于模型训练的论文,结论是:如果使用AIGC内容对模型进行训练,最后会发生数据崩溃,最终导致模型误解现实。他们不会遗忘之前训练的数据,但是会认为,野外刚出生的小孔雀确确实实长了一身绿毛。
这篇论文的结论,还指向了一个没有那么愉快的结论:模型领域的先发优势确实存在,先行者可以通过产出冗余内容的方式,污染后来者的训练数据——让后来人无路可走,先发者的骄傲尽数体现。

不过先行和先烈仅有一字之差,活下来就是先行,死了就是先烈。我们可以掂量掂量,到底哪个概率更高,明天和意外到底哪个先来。
AI如此强大,应用场景当然不止有“信息流广告”这么狭隘。就比如说AI生成图片,经常就一个主题产出好几张图,每张图都有细微的差别或者“抖动”,恰恰适合放在各种解密游戏里面,找不同,找线索,找各种奇奇怪怪的东西。
从逻辑上讲,这个道理是讲得通的。我也的确见过这样的游戏,体验一言难尽。虽然可以通过技术手段锚定每次生成的人物面部细节,但是周围模糊的背景,对游戏体验造成了不小的干扰——用AI生成图做寻物解谜,仿佛雾里探花,主打的是一个氛围感和朦胧美,令人眼酸。钱钟书在围城中曾经提到:“对于丑人,细看是一种残忍。”玩AI生成的解谜游戏,可能对我自己是一种残忍。
在今年1月,各路人马对于Open AI顶礼膜拜的时候,马斯克曾经留言:我们不需要Chat-GPT,需要Truth-GPT。在这个时间点上看,此言不虚。但矫正期待,面对现实,是只有人类能做到的事情。
这两天GPT-4模型正式发布,更多的参数,更充分的专家模型支持,更大的集群和更低的利用率。太棒了,技术本身当然可以更进一步,更进一步,直到实现通用人工智能,造福更多人的生活。但这种代价,是不是要建立在跟现实有明显偏差的基础之上呢?我们使用人工智能,是希望减轻自己的负担,同时期待它可信赖,可依靠。但如果一天天的,被“货不对板”的信息溜来溜去,造成的麻烦比没采用之前还要更多。那到底,我们是技术的主人还是工具的奴隶?
博尔赫斯曾经讲述这么一个故事:曾经有一个国王,用一张巨大的纸,绘制出王国的每个细节。这张纸实在是太大了,没有任何地方可以收纳,只能摊开在王国的土地上。最终这张耗费无数人力,精准无比的地图,逐渐腐烂,被人遗忘。
希望这不会成为这些大模型的寓言。
文|星咏
