



[玩玩聊聊] 过气小游戏,在人工智能领域“再就业”
精华2022/06/08767 浏览综合

不知道有多少人对《飞机大战》这款微信小游戏还有印象——

(曾于2013年的微信5.0版本上线)
简单复述一下玩法:玩家操作小飞机四处躲避,小飞机可以自动发射子弹,“biubiu”两下就能点杀对面一个小飞机。画面非常简陋,也没啥策略可言,只要足够专注、手眼协调,想打出高分不会特别难。
随着微信版本的更新,这个小游戏已经在微信中消失无踪。但是,有一些Python教程,会把这个作为一个比较基础的练习。毕竟能自己从头到尾编写一个“跑得动,0 error,0 warning,还能上手玩一玩”的程序,对于新手来说可比单纯的“hello world”刺激多了。

但“飞机大战”能教给用户的可不止这些。在人工智能深度学习领域,以“飞机大战”为代表的一系列小游戏,还在猛猛发光发热。B站上有非常多的相关视频,比如说ID为“vs小怪兽Monster”的这名用户,专门上传各种“小游戏VS人工智能”的内容,其中播放量最高的就是这个《惩罚人工智能,倒逼 AI 成长》(BV12h411X7yY),有兴趣的读者可以去看看。在这个视频中,人工智能悟到了《飞机大战》的最终解法:偶尔击落一下小飞机,大部分时候蜷缩在角落——只要我不主动出击,当好苟命王,就绝对不会输。
当然也托了人工智能、算法推荐的福,我很快就找到了更多的人工智能摆烂现场。其中最好玩的莫过于这个:《关于我的强化学习模型不收敛这件事》(BV1e5411R7rF)。视频讲述了一个研究自然语言处理(NLP)的小姐姐,如何入坑强化学习的全过程。李Rumor小姐姐使用的游戏是雅达利平台上的《Tennis》,她原本以为能训出地表最强的网球王子——

但实际上,经过5万次模拟,得到的却是,一个死活不发球,绝不开始游戏的摆烂AI——
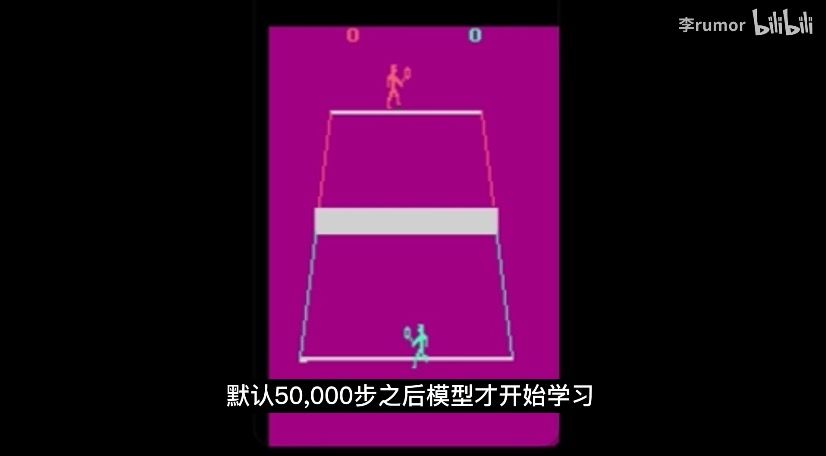
好吧,“……只要我从不下场,我就是无敌的!”
还有一个更为知名的摆烂现场:“人工智障狼”。规则是“狼吃羊”的基础规则,狼AI有20秒的行动时间,吃到越多羊越好,时间越长扣分越多。同时地面上会生成一些石头,试图模拟现实环境。但进行了20万次模拟之后,神奇的结果出现了:狼选择开局摆烂,尽一切可能,全速朝石头冲刺,一头撞死。多数情况下狼根本吃不到羊,在抓羊的过程中因为浪费时间还要被扣分,还不如一开始就一头撞死,这样扣的分还少一点。
逻辑颠扑不破简单明了,绝对理性的AI已经给出了他们自己的回答。
“等等,奇怪,”我作为一个游戏玩家的DNA动了起来:“飞机大战,狼吃羊,雅达利小游戏资源库——这些走在业界前沿的人工智能,怎么都在玩过气小游戏啊?”

(《底特律:变人》:仿生人会梦见电子羊吗?)
人工智能(以下简称AI)、算法分发,已经构成了如今日常生活的一部分,并且还在蓬勃发展中。但其实这并不是一个新鲜事物。从上古时代的神话开始,人们就希望藉由自己的双手和头脑,构建一个与自己智识类似的人工产物,也可以理解成一种“人造人”的幻想。但相关的技术和理论基础,直到上世纪90年代才出现。1950年左右,美国的一些计算机科学家们,编写出了国际象棋和国际跳棋程序,并且能挑战有一定水平的业余玩家。从那时开始,游戏AI就一直被认为是评价AI进展的一种标准。
在经历了反反复复的高潮和低谷之后,AI终于在最近10年间获得了飞速的发展和应用。而其中发展最为蓬勃的分支,就是“深度学习”这个大分类。深度学习已经是目前人工智能应用中,相对较为前沿的应用领域。根据一些新手入门教程的定义,深度学习指的是:“机器学习的一种学习路线,建立、模拟人脑进行分析的神经网络。”
而神经网络和强化学习则是深度学习的解决方式。他们主要模拟的是单智能体(agent)的探索和策略,优势在于可以同时模拟的次数较多,同时跑几千几万次模拟不费劲。或者说,在没有模型输入,一片空白的情况下,如何通过控制变量,来刺激人工智能的自主学习,最终得出问题的解决方案。
构建一个有效的神经网络,不光需要海量的信息进行输入输出,还需要不断地进行训练,调整规则以及它的权重。告诉它那些行为是被允许的,哪些行为会被惩罚,经过不断地调整和迭代,最终,才能获得一个——勉强参与游戏并且遵守规则的,弱人工智能,即“专注于解决特定领域问题”的人工智能。
这里只是一个粗略的概括和描述,让我们还是回到游戏的话题吧——为什么这些过气小游戏,能够在人工智能领域下岗再就业呢?

(公开发布的Gym documentation调试工具箱,内置了大量雅达利小游戏)
一方面,这些小游戏真的很小,占用存储空间非常小。刚刚我们提到神经网络会进行并发模拟,游戏越小,占用的存储和带宽也越小,程序跑起来也越发轻便,相应花的钱(租服务器什么的)也越少。另一方面呢,这些小游戏相对来说规则简单,方便程序员们根据数据结果进行参数调整。最后,这些小游戏并未用于商业项目盈利,仅用于研究用途,从版权角度看,也合情合理。再加上人工智能领域,有用游戏项目验证AI进展的惯例,最终,你小时候玩腻了的那些游戏,现在就成了人工智能的最好教材。
在“网球王子”视频的结尾,小姐姐的摆烂模型终于开始得分了,她表示学算法的乐趣正在于此,不断刷新自己的认识极限。评论区有个用户的评论,我觉得反映了一部分算法工程师的心态:“强化学习调参,就跟教自己***读书一样,教得心累还学不会。”
我小时候也学过一些算法基础,但很明显,为了竞赛而准备的过气知识,已经跟不上最新的版本环境了。人工智能领域的发展令人惊叹,接近于人类翻译水平的翻译工具DeepL,输入画风和指令就可以自动生成画面的Disco Diffusion,还有神经网络天花板GPT-3……他们生成的内容,可以说以假乱真。如果仅从表征来看,这些由程序产出的内容,和一些稍显相对平庸的人类作品,并无二致。

(Disco Diffusion根据关键词自动生成的图像)
在人工智能领域,“是否能通过图灵测试”,是检验人工智能发展水平的试金石。测试的规则如下:先假定有对象AB两个实体,其中一个是真人,一个是人工智能。他们都藏在不能被其他人看到的地方。这时候,有一个不知情的第三人,拿着同样的问题,分别去去征求对象AB的意见,反复多次问询后,他无法根据回答的内容,来区分AB的不同。那么我们可以认为,参与测试的人工智能,是可以通过测试的。
要达成这个目标,自然离不开多学科的共同努力,目前仍无法确定,在我有生之年,是否能见到这样厉害的人工智能。而从哲学角度看,当有人工智能真的通过图灵测试,不可避免会牵扯到“表征和实体到底那个更重要”“只要外表看起来一样,那么动机是什么,是不是都可以不考虑”的无尽论证中。
但好在,我们还没有进入到这个阶段,人工智能也没有这么聪明,还在各种算法模型中,四处“摆烂”。再强大的人工智能,也需要人类作为第一动力,去提出需求,发现疑难。而看了无数“智障”现场的我,这才认识到,对于人类来说,什么才是最宝贵的东西——提出问题的能力,不断尝试的勇气,注视着你的温柔目光,和一颗温暖的心。
文 | 星咏
