

Unity大咖作客 | 知乎大V「放牛的星星」,是这么做性能优化的
2021/07/15124 浏览综合
6月30日,「Unity大咖作客」邀请到知乎社区 Unity 引擎领域专家放牛的星星和Unity 大中华区技术经理金晓宇,跟大家聊了聊性能优化。

放牛的星星从定义、维度、常用工具等方面讲解性能优化,无论是新手小白还是技术老手都受益匪浅。深入浅出的讲述方式让观众们纷纷把“666”“感谢浩哥”打在了公屏上。
金晓宇以GPU的性能优化为主题带来了硬核干货分享,大家全程紧盯屏幕,生怕错过技术要点。
本文为大家摘录了性能优化专场的精彩内容,完整录播已上传至 B 站。
B 站观看地址:
Unity移动游戏优化 – 性能优化维度与工具
大家好,我是放牛的星星,非常荣幸为大家带来一期以性能优化为主题的技术分享。本次的主要内容是探讨如何优化Unity的移动游戏。
本次分享有以下四个主题:第一是探讨性能优化的相关信息;第二是探讨性能优化的相关维度;第三是了解一下常用的性能优化工具;第四是拓展一下在性能优化路上的更多可能性。
第一是性能优化。
究竟什么是性能优化呢?我的个人总结,性能优化实际上是纠错使用、相互平衡以及充分利用软硬件资源的过程。

我们看纠正错误使用,实际上是解决几个层面上的问题。比如说对语言特性的不了解,对引擎特性的不了解,以及对目标平台特性的不了解。
对于语音特性的不了解可以简单举一个例子,因为Unity使用的脚本是C#,C#里面一个导致性能问题的方式就是装箱。装箱实际上是C#将一个值类型向一个引用类型转变的过程。比如说我们现在看到的示例。

这个string.format的时候,实际上是将一个int值装箱成了string值,然后才能拼接成字符串。当一个引用类型被处理的时候,也就是说我离开了这个作用域,需要GC的时候,就会产生一些垃圾,就会造成一个不必要的性能损耗。
第二个是对引擎特性不了解,实际上我们可以表现在一些常用的脚本上面,比如说如果用Unity创建一个默认的MonoBehaviours的时候,里面会有一个空的update的方法。假如你不删除这个update方法的话,虽然它是一个空方法,但是仍然会有比较高的性能损耗。下面这幅图上是我从Unity官方网站上找到的一个案例。
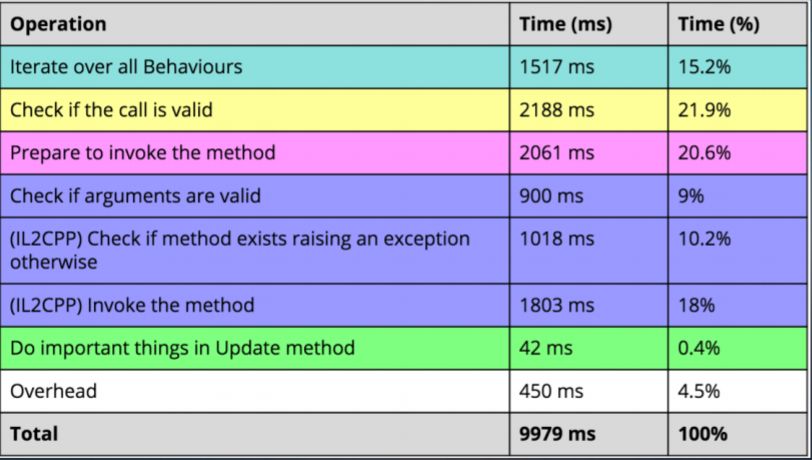
10000 个 MonoBehaviours空方法调用
实际上是执行了一个一万次的空方法调用,从上往下看只有在最下面的时候,那么一点点损耗的时间是用来做update里面实际上的空逻辑方法的。大部分时间都是在C++往C#层调用的时候,这个过程当中产生的。所以说即使我们不要用的话,也需要把update函数去删掉,如果不删掉的话可能会造成性能问题,这也是常规的大家会忽略的引擎的一些特性所造成的性能问题。
还有一种是对目标平台特性的不了解,实际上我们都知道不同的硬件平台所支持的GPU的纹理格式是不相同的。如果没有选对平台上的纹理格式,或者直接使用RGBA或RGB纹理格式,实际上在内存和带宽会导致非常大的性能问题。我们如果了解这些目标平台特性的话,实际上就会为这个平台选取最合适的纹理格式。
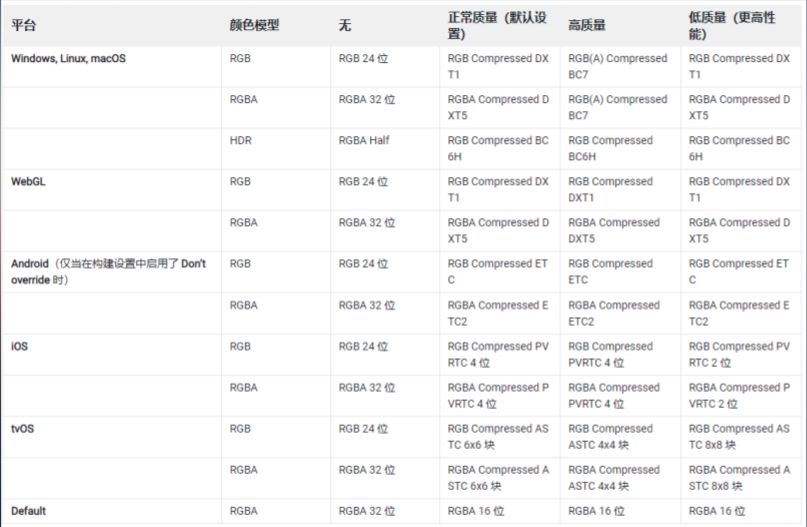
第二个点就是相互平衡。相互平衡就是用一种资源去换取另外一种资源,比如说loading速度比较慢,或者加载速度比较慢,实际上是可以把加载好的这些资源进行缓存,然后用内存去换取IO的读取速度。比如说像CPU执行比较长,或计算耗时比较高的时候,也可以把结果缓存起来,用内存换取CPU执行时间。当然像一些比如说骨骼节点、蒙皮计算等等,如果CPU消耗时间比较长,也可以用动态骨骼的方案或者说GPU skinning的方式,将CPU损耗开销到内存和GPU上面去。这些都是一个相互平衡的案例。
实际上在游戏开发过程中,这种相互平衡是处处可见的,大家需要根据自己的性能瓶颈的卡点处来决定这些方案的执行。
充分利用软硬件的行为,最典型的是Unity的DOTS,基于数据栈的编程方式。这个方面,我们是充分利用了多核的特性。还有 GPU Driven,它是近段时间或近年来频繁听到的一个词。根据我的个人理解,GPU Driven不是很具体的方案或者完整的解决流程,而是一种思想——我们应尽可能地充分利用现代GPU的性能特性,尽可能将工作从CPU端释放出来,以GPU算力为准,然后充分利用GPU的算力。最后是像Unity的多线程渲染等等,这些技术实际上都是在充分利用现代硬件的特性。

接下来看一下对性能优化还关注哪些维度?从我个人的感觉来说,我们可以把一级性能维度归咎为CPU、GPU、内存、IO的四个层面。关于一级性能维度,后面我还会详细讲,这里就大概列一下。

下面我们要关注一下性能优化的行业现状大概是什么样的样子呢?
目前我个人的经验,就是现在的行业现状,第一个是缺认知。缺认知的意思,实际上又分为两个层面,第一个是项目或者是公司缺乏一个性能优化的认知,并没有把性能优化从立项期就根植到项目的骨髓里面去,往往很多项目在上线前临时抱佛脚进行一次突击式优化,这样实际上是治标不治本的。因为优化的成本越高后期,成本就越高。我们如果能够从一开始就对游戏开发有性能优化的认知,从最开始就开始小步迭代性能的话,到最后上线之前是不会有非常大的性能问题的。
如果真正到了那个时候有非常大的性能问题的时候,再去发现问题,然后再去调整的时候,你会发现很多掣肘的地方,包括方案不能改,妥协的地方没有办法动,这个是非常被动的。
第二个是开发人员缺乏认知。性能优化的认知是建立在开发人员有一定经验的基础上面,才能去知道我写的每一段代码,或者我写的解决方案存在哪些问题,或者说有哪些好处。大部分大家在写代码的过程中以实现为主,对性能的考量并不是特别多,这也是过往我的经验当中发现比较多的类似的问题。
其次是缺标准。缺标准的意思是在性能优化过程中没有完善的标准或者体系,能够让所有的项目去遵从这个事情,或者说能够让项目看一眼,或者学习一段时间,就能够批量或者流水线的方式去解决性能问题。目前来说,是没有一个这样的标准。不管可能是因为公司,或者是项目本身的人才质量,也可能是公司本身的一些环境等等导致的。包括性能优化,实际上也是近几年才被各个公司所重视的,所以在这个层面上面是没有一个统一的标准。包括对于不同类型的游戏来说,也不能以一概全。
第三是缺人才。性能优化是建立在有一定工作经验基础上的,相对来说还是比较吃经验的。我会在最后面的会去总结一下人才的相对标准,这一块可以放到后面去说。

现在我们既然没有标准,是否有可行性的岗位实践和职位现状呢?我这边总结了一点点,大概总结了四个职位信息。
第一是程序。因为大部分的时候代码或执行效率都是由程序来实现的,最大的问题实际上也是在程序方面需要去解决的。这个时候,程序这个职位是必不可少的。
第二是TA。TA是负责渲染或图形层面的内容,在图形层面也会产生比较大的性能问题,比如说Overdraw、剔除等等,跟图形相关的一部分是需要TA帮助解决的。
第三是QA。性能的QA,实际上是需要了解整个性能这一条链路,或者管线上面所关注的性能指标。然后通过程序或TA提供的工具,能够监控和发现性能问题,然后能够验收或者回归解决完的性能问题,这是一个性能QA的标准。
第四是PM。为什么我们会提到PM呢?因为很多性能问题的解决方案可能是需要美术参与,比如说特效的性能问题,可能要更改特效的执行流程,或者是特效的制作方式。比如说我们的纹理格式、切图方式等等跟美术相关的部分,实际上大部分的美术人员对于性能并不是特别敏感,基本上都是由项目这一块执行完了标准之后交给美术,美术按照规格去做图。一旦标准改变了之后,就需要美术人员去改动标准,或者是按照新的标准去做事情,这个时候因为美术的体量比较大,他是需要PM去跟进这个事情的。这个是职位现状。
放牛的星星后续还分享了性能优化的相关维度、常用的性能优化工具以及性能优化方面的更多可能性,完整录播尽在 B 站「Unity官方」频道。
GPU 的性能优化
金晓宇:大家好,我今天要跟大家分享的主题是GPU的性能优化。下面让我们先来看一下分享的概述:
首先会先介绍Shader常用的优化和要注意的点;接着跟大家分享或者介绍一下GPU Occupancy&latency是什么,以及对性能会做出哪些影响;最后会针对移动端的Tile-based Rendering给出一些分析及优化的建议。
首先是针对Shader指令的一些优化。
我们使用最合适的一些数据类型是比较好的,可以使编译器和驱动去优化代码。比如左边绿色方框的代码,int4 foo这是一个Shader里的函数,它的输入是一个int4 x,然后返回是一个x + 1。通常来说,这段代码经过编译器优化之后,通常只需要一个指令就可以完成。右边的int4红色代码,和左边唯一不一样的地方,就是return x + 1.0,这个代码是十分不友好的,通常需要8个指令才能完成。因为1.0需要转换为foo4,然后再从foo4转化为int4,正常需要8个指令来完成。可见一点点的隐式转换就可以大大地增加指令的消耗,我们应该尽可能避免隐式转换的操作。

建议尽可能把标量数据pack成向量,可以提高硬件GPU的读取效率。而指令的缓存是经常被忽略的地方,而它可以影响GPU上warp或者wavefront运行的一个线程数量,应该尽可能缩短Shader着色器的代码。而且一个较短的Shader着色器,更有可能在高速缓存中命中。

下面来谈精度,首先是顶点属性的精度。并不是所有的顶点属性都需要FP32的高精度,比如说颜色、法线,资产管道应该将数据保持在所需最低的精度,这样做可以减少带宽,并且提高性能。

而且Mali GPU可以在数据加载的时候,将属性免费转换为FP32。这样使用较低的数据精度、数据类型,不会产生额外处理器的开销。
所以给大家这几个建议,比如顶点position需要额外的精度,可以使用FP32来计算顶点位置;其他属性使用低精度,只有在需要的时候才提高到高精度;还有不要把FP32数据上传到buffer,然后再作为一个低精度属性来在Shader里读取。这样做会浪费内存的存储和带宽,因为额外的精度就被丢弃了。
下面再来谈一下VS输出数据varying的精度,我觉得尽可能减少varying的精度是很重要的。因为这样做可以减少varying所需的内存、存储、带宽的数量。而且也会间接地影响Shader占用的寄存器的数量。特别的、更重要的是移动端GPU,因为在执行FS或PS之前,都会被写回到System Memory里,相比于IMR架构来说会有更高的带宽的消耗。
再就是确保每一个varying的数据,都能在FS里用到或者PS里用到,换句话说,不要输出给FS没有用到的varying数据。
一般从经验上来说,以下的数据可以用低精度,比如法线和切线,他们用FP16是足够的,因为他们都是nomalized,他们的取值范围在 -1到1之间,用低精度是够的。顶点色等颜色对精度并不敏感。还有小于等于512×512的纹理的UV,这样就是足够的。
还有一些数据建议用高精度,世界坐标就不用说了,还有一个是大纹理的uv或者wrap mode是repeat的uv。因为当这个uv取较大的一些值的时候,可能需要更高的精度。

接下来再聊一聊buffer和寄存器,我们知道当使用寄存器过多的时候就会降低warp的并行性,warp是Nvidia显卡GPU的概念,之所以会这样,因为SM(Streaming Multiprocesser)寄存器数量是固定的,寄存器会平均分配给运行的一些warp。当Shader需要的寄存器越多的时候,生成的warp就越少,可以切换的warp就越少。我们在等待指令完成的时候,比如说在等待Texture Fetch的时候可以做的工作就越少,GPU可以做的工作就越少。
举个例子,在URP里,多光源的shading就改为了一个pass来执行。相对于多pass的shading可能并不能带来多少性能的提升。因为如果是GPU Bound的话,更多的光源就占用了更多的buffer,使用了更多的寄存器,间接就影响了warp的数量,运行时并行性就会下降。
根据我个人的理解,多光源单pass shading主要降低的是CPU消耗,而不是GPU的。
另外是如果寄存器使用太多的话,会造成一个寄存器溢出的现象。寄存器溢出后,会导致GPU从System Memory里来读取,比如说Uniform Buffer之类的,这就加重了fetch data的消耗。
我们怎么来减少寄存器的使用量呢?寄存器的使用量通常由以下因素决定的,比如说Uniform Buffer的数量、变量数量,包括临时变量,还有varying的使用的数量。所以说大家在编写Shader的时候,可以尽可能减少这些东西的用量。
再一个,Uniform Buffer和SSBO使用哪个更好一点。这里的建议,如果Uniform Buffer足够小的话,驱动可以把他们影射到硬件的Ram里,此时它的访问会比SSBO更高效。比如说Mali的GPU可以把Uniform的数据提交给Shader寄存器,这些数据就可以在每个draw之前加载,而不是在每个Shader thread上加载,如此就减少了大量读取的操作。建议Uniform Buffer适合的话,就尽可能用Uniform Buffer,而不是SSBO。

接下来再说一下Texture Fetch,我列了几条大家平常用到的。第一个是尽可能避免随机访问。第二是访问3D纹理的代价通常会较高,这也是比较符合我们直觉的。第三是尽可能减少Texture Fetch,这条只是一般来讲都会提高性能。第四是压缩纹理,这个是一定要做的。第五是使用mipmap。平均来看,各向异性filter的消耗大概是各向同性的两倍。
在Mali CPU上,一些Texture Fetch采样的消耗,比如说在3D Texture会有两倍于2D Texture的消耗。FP32数据格式会有两倍消耗。一般来说,对于大部分GPU来说,cube map 采样每个面的消耗,通常和采样一个2D Texture的消耗想等。

最后来聊聊 Branching,也就是Shader里面的一些 if 之类的。首先我们都知道if语句会增加GPU的开销,主要做的就是降低warp的并行性,降低了SM的吞吐量,所以我们应该尽可能减少动态分支语句。所谓的动态分支语句在运行时才能确定是哪个分支的语句。我们通常可以用一些函数,比如max、min减少一些比较小的分支语句,相信大家都已经比较熟了。
还有一种分类是静态分支语句,这种一般是可以接受的。何为静态分支语句呢?就是我们知道Shader的执行一般是以线程组为单位来运行的,所以当warp走的是一个分支的话,这个分支就不会出现一个既执行分支A,又执行分支B的情况。此时对于SM吞吐量的影响就比较小了。对于最常用的静态分支,就是uniform变量作为条件的动态语句了,因为uniform变量在每一个DrawCall里面都不会变的。
最后一个,就是early quit的分支语句有时候可以提高性能,比如说在计算点光源的光照时,可以首先计算一下着色点到光源的距离。如果大于光源的影响范围的话,就可以提前退出。虽然这个语句肯定是会影响SM吞吐量的,但是由于多数的warp走的是同一个分支的话,如果可以尽早退出的话,还是有可能提高性能的。

接下来再聊一下Loop,也就是循环。一般针对Loop,通常用unroll来展开循环,可以减少flow control的数量。不过我们要展开的话,Loop的循环在编译器决定的,编译器才能够通过unroll的标记来展开循环,就可以减少Shader代码中control的数量。
但是它也有一点副作用,因为它会增加寄存器的用量。如果在循环里会采样一些Texture,比如说ray marching的时候,他会倾向于把Texture Fetch放在Shader的顶部,就可以间接增加寄存器的用量。如果循环次数不多的话,我建议还是手动展开会比较好。最重要、最好的就是确认一下展开和不展开前后的一个实际性能消耗,对比一下是最好的。
下面介绍一个对于ray marching类似的循环结构,每个循环可以多次进行优化。比如说ray marching中每个循环可能会采样一次depths,这里的问题就是说如果在循环里面的warp有可能并不能完全掩盖Texture Fetch的延迟。关于延迟,我后面会花一点时间来介绍一下。所以一个比较常用的办法,就是每个循环采样两次depth,通过把两次Fetch语句紧挨在一起,然后可以利用编译器的优化把Texture Fetch batch起来,这些Fetch就可以并行地来执行。
原本两次Fetch的延迟优化为一倍的延迟。当然在实践中还是要profiling,如果profiling优化有用的话,可以甚至更激进一点,每个循环去步进更多步进比如说四次,然后一点一点去优化到最优的性能。

金晓宇老师还介绍了 GPU Occupancy&latency及其对性能的影响;并针对移动端的Tile-based Rendering给出了实用的分析及优化的建议。

本期「Unity 大咖作客」完整版已经上传至 B 站,欢迎大家关注 B 站「Unity官方」频道: